MoreFusion
Multi-object Reasoning for 6D Pose Estimation from Volumetric Fusion
Robots and other smart devices need efficient object-based scene representations from their on-board vision systems to reason about contact, physics and occlusion. Recognized precise object models will play an important role alongside non-parametric reconstructions of unrecognized structures.
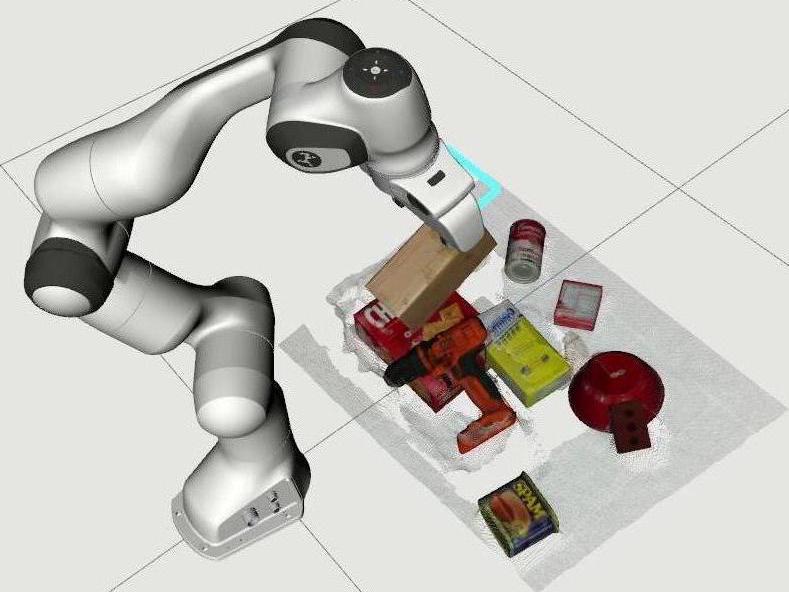
In this paper, we present a system, MoreFusion, which can estimate the accurate poses of multiple known objects in contact and occlusion from real-time, embodied multi-view vision. Our approach makes 3D object pose proposals from single RGB-D views, accumulates pose estimates and non-parametric occupancy information from multiple views as the camera moves, and performs joint optimization to estimate consistent, non-intersecting poses for multiple objects in contact.

Overview Video (with audio)
Pipeline
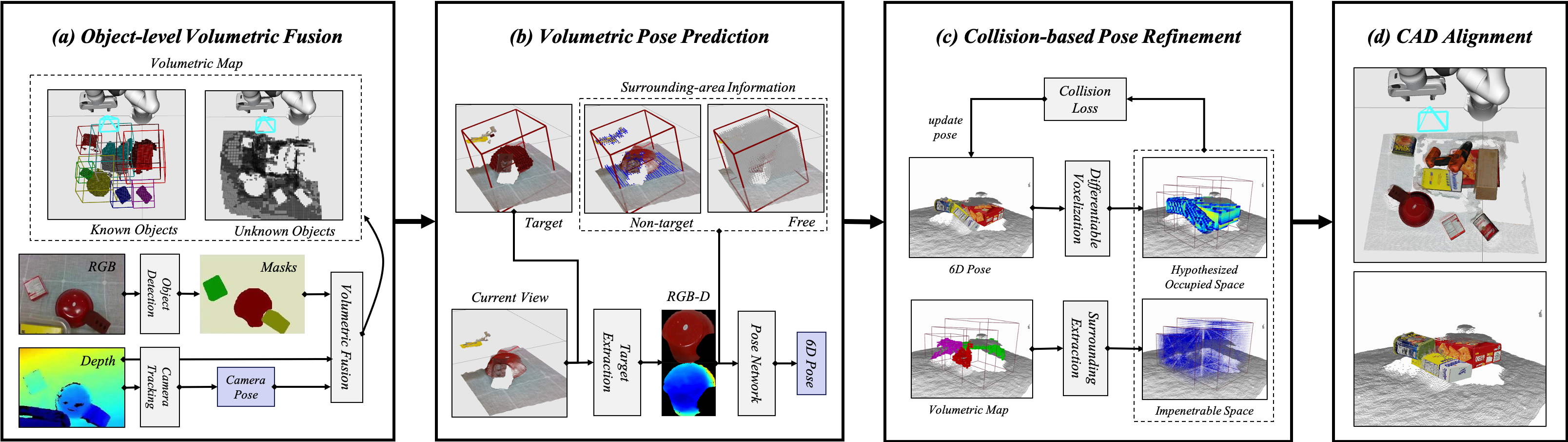
We present a pipeline that achieves state-of-the-art results for 6D pose estimation of known objects, which (a) reconstructs a scene with volumetric fusion; (b) predicts object pose utilizing the volumetric reconstruction; (c) refines the predicted pose respecting surrounding geometry and pose predictions; (d) validates plural pose hypothesis to find a highly confident pose estimate.
Surrounding Spatial Information
Each target object for pose prediction carries its own volumetric occupancy grid. The voxels that make up this grid can be in one of the following states: b) Space occupied by the object itself from the target object reconstruction; c) Space occupied by other objects; d) Free space identified by depth measurement. e) Unknown space unobserved by mapping because of occlusion and sensor range limit.

(a) Scene
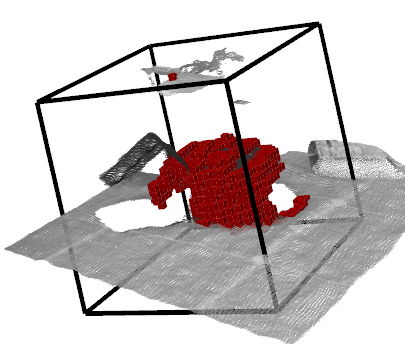
(b) Grid (self)
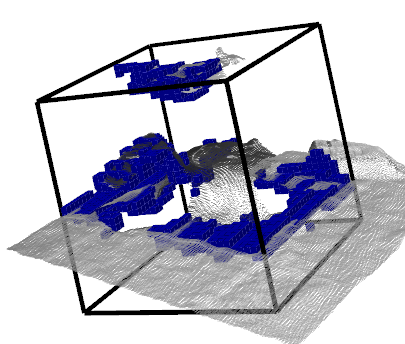
(c) Grid (other)
(d) Grid (free)

(e) Grid (unknown)
Pose Prediction Results
Our proposed model (MoreFusion) performs consistent pose prediction with surroundings, where the baseline (DenseFusion∗) and the variant without occupancy information (Morefusion−occ) fails.
| Scene | DenseFusion* | MoreFusion-occ | MoreFusion | Ground Truth |
|---|---|---|---|---|
 |
 |
 |
 |
 |
We evaluated the pose prediction in different datasets (YCB-Video, Cluttered-YCB), and the result shows that the proposed model consistently gives better pose estimate than the existing method.
| Model | Dataset | ADD(-S) | ADD-S |
|---|---|---|---|
| DenseFusion* | YCB-Video | 88.4 | 94.9 |
| MoreFusion | 91.0 | 95.7 | |
| DenseFusion* | Cluttered YCB | 81.7 | 91.7 |
| MoreFusion | 83.4 | 92.3 |
As more and more occupancy information is available: MF-occ (no occupancy) < MF < MF+target- (full grid of nontarget), MF+target- +bg (full grid of background objects), the model gives better pose estimate.
| Model | ADD(-S) | ADD-S |
|---|---|---|
| MF-occ | 82.5 | 91.7 |
| MoreFusion (MF) | 83.4 | 92.3 |
| MF+target- | 84.7 | 93.3 |
| MF+target- +bg | 85.5 | 93.8 |
Pose Refinement Results
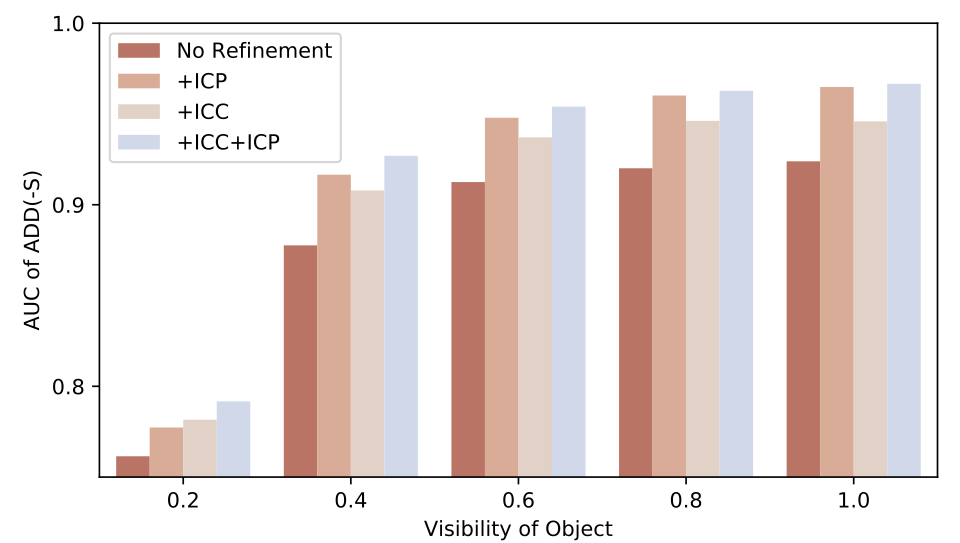
The proposed collision-based pose refinement, Iterative Collision Check (ICC), gives better convergence minimizing the intersections among objects, as well as aligning the model surface to the depth observation. For detailed refinement (right figure), it is better to combine ICC with Iterative Closest Point (ICP), to initially align model with ICC in volumetric resolution and then to refine the detail in point space with ICP.

Scene Reconstruction
Robotic Top-down Camera Sequence

Table-top Side-view Camera Sequence

Robotic Pick-and-Place
Pick the Target Object (Red Box) from a Pile

More Examples...

Paper

Bibtex
@inproceedings{Wada:etal:CVPR2020,
title={{MoreFusion}: Multi-object Reasoning for {6D} Pose Estimation from Volumetric Fusion},
author={Kentaro Wada and Edgar Sucar and Stephen James and Daniel Lenton and Andrew J. Davison},
booktitle={Proceedings of the {IEEE} Conference on Computer Vision and Pattern Recognition ({CVPR})},
year={2020},
}
Contact
If you have any questions, please feel free to contact Kentaro Wada.